This is priceless as one of the phpBB spamming idiots from Russia messed with the wrong webmaster this time who now owns his spamming ass.
You just have to read this DRC forum post to believe anyone could be so stupid.
Thanks to SpamHuntress for pointing this out.
Friday, December 01, 2006
Webmaster Owns Spammers Ass
Wednesday, November 29, 2006
Dear Amazon AWS Group
To whom it may concern,
Your bot crawled my site today as shown below. Please notify your engineers, and I use the term loosely, that "Java/1.5.0_09" is not a valid bot name. Being that Amazon sells books on how to program Java, I'm sure you can find at least one book in your warehouse that will explain how to set the User Agent string when making web requests.
Additionally, would honoring ROBOTS.TXT be too much to request or do you feel justified not checking the robots file since your programmers can't figure out how to tell us what your bot name is in the first place?
216.182.236.241 [domU-12-31-34-00-00-B9.usma2.compute.amazonaws.com.] "Java/1.5.0_09"It makes me weep for the future when a big web conglomerate, one that has a name that is synonymous with buying things online, one that should know better, starts to slide down that slippery slope of being a bad netizen.
216.182.236.142 [domU-12-31-34-00-01-1E.usma2.compute.amazonaws.com.] "Java/1.5.0_09"
216.182.236.177 [domU-12-31-34-00-00-F9.usma2.compute.amazonaws.com] "Java/1.5.0_09"
216.182.236.110 [domU-12-31-34-00-00-2A.usma2.compute.amazonaws.com] "Java/1.5.0_09"
216.182.236.167 [domU-12-31-34-00-01-07.usma2.compute.amazonaws.com] "Java/1.5.0_09"
216.182.233.105 [domU-12-31-34-00-01-D3.usma2.compute.amazonaws.com] "Java/1.5.0_09"
216.182.230.187 [domU-12-31-33-00-03-55.usma1.compute.amazonaws.com.] "Java/1.5.0_09"
216.182.237.9 [domU-12-31-34-00-01-B5.usma2.compute.amazonaws.com.] "Java/1.5.0_09"
Signed,
Get A. Clue
SiteAdvisor and ThePlanet Must Not Care
There were several hits my blog post about SiteAdvisor from Network Associates, that owns McAfee SiteAdvisor, yet nothing changed. Wouldn't you assume that after reading my posts about SiteAdvisor Green Lighting sites with the worms in them that someone would at least change the site status to protect people.
Nope.
Funny, Symantec's Norton AntiVirus agrees with me that the site has a worm, but SiteAdvisor says you're good to visit.
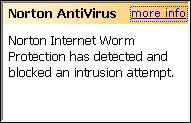
Maybe they don't think it's a threat because McAfee AV products don't detect this worm?
Who knows, I'll stick with Norton AV.
Then again, we have ThePlanet that hosts these sites, and they were notified 6 days ago that this problem existed on 4 of their servers and these sites are still online and functional.
I guess nobody cares about security these days.
Who knows, I'll stick with Norton AV.
Then again, we have ThePlanet that hosts these sites, and they were notified 6 days ago that this problem existed on 4 of their servers and these sites are still online and functional.
I guess nobody cares about security these days.
Tuesday, November 28, 2006
BDFetch Plays By The Rules
Normally I'm always slamming corporate bots but when one company, like brandimensions appears to be playing by all the rules, I feel they should get a little praise.
Here's what their access attempts look like:
209.167.50.22 "GET /robots.txt HTTP/1.1" "www.brandimensions.com" "BDFetch"At least they asked for robots.txt and appear to only go in when allowed.
209.167.50.22 GET /somepage.html HTTP/1.1" "www.brandimensions.com" "BDFetch"
209.167.50.22 "GET /robots.txt HTTP/1.1" "www.brandimensions.com" "BDFetch"
209.167.50.22 GET /somepage.html HTTP/1.1" "www.brandimensions.com" "BDFetch"
209.167.50.22 "GET /robots.txt HTTP/1.1" "www.brandimensions.com" "BDFetch"
209.167.50.22 GET /somepage.html HTTP/1.1" "www.brandimensions.com" "BDFetch"
However, they had a couple of bumps that I'd like to see them fix.
1. Ask for robots.txt once or twice a day, maybe once an hour worse case, not every access.
2. Set your reverse DNS to say bdfetch.brandimensions.com or something similar so we can verify it's really your company and not someone spoofing you.
3. Include a link to a page about your crawler in the user agent, and a version number, such as ""BDFetch/1.0 +http://www.brandimensions.com/crawler.html"
Other than those minor glitches, kudos for at least trying to play by the rules and at least giving webmasters the choice to allow you to crawl or not.
Nicely done.
Legality of Stealth Robots, Are They Trespassing?
What is the legality of a stealth robot, are they doing anything wrong?
Take a look at "Computer Hacking and Unauthorized Access Laws" and you'll see there's a quagmire of various laws but the topic that's most relevant to this discussion would be "Unauthorized access" which basically covers trespassing onto a computer, theoretically even if that service is a public web server as the laws don't specify the server or service has to be private.
I'm no lawyer, so this obviously isn't valid legal advice, just my musings over the content of the California law, particularly the definitions in 502.c:
(c) Except as provided in subdivision (h), any person who commits any of the following acts is guilty of a public offense:Let's examine what these transparent stealth crawlers do and see if it fits the definition.
(1) Knowingly accesses and without permission alters, damages, deletes, destroys, or otherwise uses any data, computer, computer system, or computer network in order to either (A) devise or execute any scheme or artifice to defraud, deceive, or extort, or (B) wrongfully control or obtain money, property, or data.
(3) Knowingly and without permission uses or causes to be used computer services.
First, the people using stealth crawlers know if they use a real user agent like "Bob's Bot 1.0" that it will expose their presence and they will be blocked. To avoid this, they mask their presence which obviously falls under "knowingly accesses and without permission" to get to the content on the web site attempting to block their trespass.
Second, after they have gained access they "wrongfully control or obtain ..., property, or data" and do with it as they please, republish without permission, use to compile reports, etc., so I think we've covered two aspects here.
Even if the act itself causes relatively little harm, there is still a potential for penalty.
(3) Knowingly and without permission uses or causes to be used computer services.The obvious solution for the crawler to be technically "legal" is to simply identify the bot by an obviously unique name like "Bob's Bot 1.0" and stop trying to spoof the web server as being Internet Explorer or Firefox in order to gain access.
(A) For the first violation which does not result in injury, and where the value of the computer services used does not exceed four hundred dollars ($400), by a fine not exceeding five thousand dollars ($5,000), or by imprisonment in the county jail not exceeding one year, or by both that fine and imprisonment.
I'd be curious what some legal minds might think about this interpretation of these laws for this particular application.
Sunday, November 26, 2006
Huge Made for AdSense Scraper and Spammer Operation Unveiled
The downside of scraping the wrong webmaster is that your websites now contain breadcrumbs that let that webmaster unravel a big chunk of your network of sites that you've been scraping and spamming.
I'm not going to even go into the list of domains I found my scrapings on as it's a huge list and the specific sites I found were all hosted on theplanet.com and 800hosting.net.
Besides, if I expose the list this MFA scraper spammer might figure out how I unraveled his system and we wouldn't want that, now would we?
I'm not even going to bother with the IP they were scraping from or the user agent since it was a spoofed browser UA of course, and the IPs doing the scraping were all from the same hosting companies listed below.
Instead, let's start at the top of the iceberg with their statistics pages listing 400-500 sites per page which in total roughly links to about 6,500 individual scraper sites, and I'm sure we're just touching the surface here.
http://www.badhood.info/So where do these sites host?
http://www.browserbytes.com/
http://www.csprovisions.com/
http://www.inbounders.com/
http://www.jewelrydns.info/
http://www.landingdns.info/
http://www.link-magic.com/
http://www.link-pros.com/
http://www.multithreedns.info/
http://www.multitwodns.info/
http://www.sfte.info/
http://www.terrificdns.com/
http://www.trafficsupply.com/
http://www.virtual-domains.com/
badhood.info 70.87.137.2 -> 2.89.5746.static.theplanet.comThere you go, it could've been a been long spew of data but there's really nothing you need to know except BLOCK access from data centers and you'll be a bit more secure, which I've been preaching for quite some time.
browserbytes.com 74.52.26.194 -> c2.1a.344a.static.theplanet.com
csprovisions.com 74.52.29.2 -> 2.1d.344a.static.theplanet.com
inbounders.com 66.98.156.98 -> evolution.cia.sk
jewelrydns.info 69.41.183.122 -> (800hosting.net)
landingdns.info 66.98.132.73 -> ev1s-66-98-132-73.ev1servers.net
link-magic.com 64.246.60.95 -> rs-64-246-60-95.ev1.net
link-pros.com 64.246.60.50 -> ns1.s810.net
multithreedns.info 74.52.225.194 -> c2.e1.344a.static.theplanet.com
multitwodns.info 74.52.126.130 -> 82.7e.344a.static.theplanet.com
sfte.info 70.87.216.194 -> c2.d8.5746.static.theplanet.com
terrificdns.com 66.98.132.68 -> damon.screaminghost.com
trafficsupply.com 66.98.250.34 -> (Everyones Internet)
virtual-domains.com 66.98.198.44 -> ev1s-66-98-198-44.ev1servers.net
Now, let's look at a specific site like fashionmenclothingjackets.info and you'll see how they really spam the search engines with 3 digit subdomains. All of their sites are like this and there are literally hundreds of thouands, if not millions, of junk pages associated with this one group of domains.
And we'll take a peek at another of these sites, like fiftiesteenagefashion.info, to see how they promote themselves with blog and forum spam for traffic.
There you have it all with scraping, search engine spam and blog and forum spam all tied up in one neat little package.
Enjoy.
P.S. Did we piss on someone's cornflakes?
Getting a ton of hits to this post via a forum on http://www.pginsider.com/ which makes you go Hmmmm.... it's amazing how they out themselves once you post something.
Anti-Phish Shootout: Firefox 2 vs. MSIE 7
Another phishing email arrived today so I tried it in both Firefox 2 and MSIE 7 as fast as I could get the link pasted into the browsers.
The resulting screenshots below and the score is:
FIREFOX: 1
INTERNET EXPLORER: 0
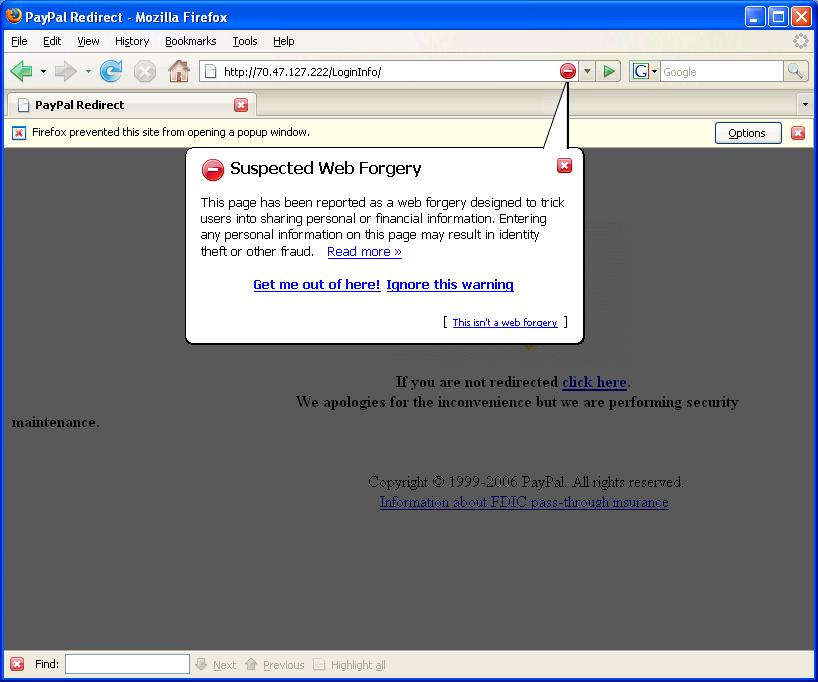

Maybe Microsoft should hire some of the Firefox developers so they can show them how to do anti-phish properly.
Subscribe to:
Posts (Atom)

