In a rather lengthy debate with the owner of Majectic-12 on WebmasterWorld the issue of robots.txt came up over and over and I finally revealed that robots.txt is arcane and a real problem in the world of scrapers as it gives them clues to accessing your content.
Not only does robots.txt reveal which user agents may be blocked in the .htaccess file but it also reveals which agents are allowed into your server. Any roque bot not getting access to your site can simply examine the robots.txt file and use any allowed user agent name to get past the barracades.
My recommendation is to use a generic robots.txt file such as follows:
User-agent: *
Disallow: /stayout.html
Disallow: /keepaway.html
Disallow: /cgi-bin/
Disallow: /someotherdirectory/
Then allow and disallow robots privately in your .htaccess file only to keep that information away from prying eyes and give the lamest of the scrapers fewer clues how to penetrate your site's defences.
UPDATE: the Majectic-12 conversation at WMW is on hold pending review now so maybe I spilled to many beans on site security issues. It was a great debate, hope it comes back only slightly altered.
Saturday, February 18, 2006
Robots.txt gives Bad Bots clues to access
Cornucopia of Random User Agent Strings
When my bot buster first started operating I noticed a few gibberish user agent strings now and then as I'm sure the theory behind this is if a website is blocking known user agents then you can skirt past that technique with a string of gibberish.
The problem is that they've noticed nothing is getting thru and random user agent string usage against my site is escalating to the point it's hysterical to witness them thrashing.
Small sampling of thousands the other day:
66.148.68.37 2uigq2oecesvv2nwso rwiakBsBue Bobgw2nuBThis is why I keep preaching that blocking by user agent only works for the legit crawlers that want to allow you to block them but the scrapers aren't playing by any of the old rules and I'm shocked these idiots just didn't use a browser string which has a better chance at least getting a handfull of pages of my web site until they get too greedy.
202.125.44.200 efeSthqvkr11ticgo1iovjjrdwakbbd
66.148.68.34 emwx4cxnd pedafhfpac
66.148.68.34 ymdexin7xpebtulwnxew
202.125.44.199 pepgfu wjdjqrxckulhwiflmrdsmkc mjvldn
84.180.94.183 mairwthe Ifirpl8tiwotwyi lsu
84.180.94.183 r9Hreiynmkxmpjh ioHmmknpdmid
66.148.68.34 ewoqaohlcegoD emkdywx
66.148.68.34 obtDrqhxogxsewDfcDktb
209.190.21.100 bedmdFjkFhc4a noFjajakffieapvngdtpwxk
209.190.21.100 gdouk6Ss6nnykg66hvojc6txjsecuu
209.190.21.100 aphErvbtijj vulgctlslo
209.190.21.100 jgbhwntsdlprxcwogijI8orrw b8
209.190.21.101 DrbspcgyubxrpeikfiihxD mh
209.190.21.101 jvAhnviAjwwud8gymvewtcqhehgbAcytyqdxq
209.190.21.101 cvwkvl6kfujhqlujqblFl dffrepmrxdspmdFjq
209.190.21.101 obmJJkjtslbqreh6pwx6epruhptrpJbk
Sorry webmasters but the rules have changed in how this game is being played and you really need to block all non-browser agents and allow legit crawlers like Google, Yahoo and MSN by IP only. Any other method is just wasting your time as random user agents cannot be stopped by your old traditional techniques.
The blacklist is out, the whitelist is in.
Wednesday, February 15, 2006
Fuckers For Sale!
Found this little gem while playing around with AdSense testing relevant ads on dynamic search pages by using a GET vs a POST and just for shits and giggles added "?q=fuckers" to the end of the URL.
Well, much to my surprise one of the ads was extremely relevant and not only that, it appears you can compare places that sell fuckers on shopping.com and get a fucker of your choice for the best price!
I don't make this shit up, see it for yourself: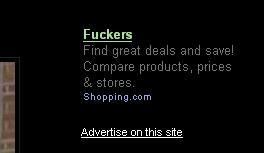
So much for family friendly AdSense ads!
Tuesday, February 14, 2006
Some days it seems so obvious
Today I was looking in the search engines for more signs of scrapers showing up in the SEs with my error messages and found a few more of these idiots. Then it crossed my mind that it would sure be nice to know which IP addresses that got blocked from scraping were assoicated with which web sites.
Well duh.
It's obvious I need to embed a bug in my text that ties the scraper to his web site so today starts the next wave of linking the abusers to their websites and opens up opportunities for automatic abuse reports that tie them all together.
Now this has me giddy, I can hardly wait!
Crawl Delayed RSS
Sometimes interesting solutions to problems just present themselves out of the blue as a discussion about Aaron Pratt's SEOBUZZBOX being supplemental results instead of the authoritative source gave me an idea.
What if you simply delayed updating your RSS feed until Google, Yahoo, etc. had already crawled your new content pages?
Theoretically this would improve your chances of being the first place that the new content was discovered and the news aggregators would then all become secondary sources for your information.
Would Google still make SEOBUZZBOX a supplemental result because of it's lower page rank or would fresh original content float to the top based on a first come first served basis and make the aggregator take the hit on duplicate content?
This is an experiment well worth trying, Aaron, you listening?
Anyone got any guesses what would happen?
Carnival of Scraper Sites
These circular scraper sites must be the worst sites I've encountered so far as all the scraped content is linked internally and no matter what you click on you just keep going round and round inside the scrapers web site until you click on an advertisement to escape.
These come in a couple of flavors such as the Moron Loop-de-Loop, the Loser Landing Strip and the Doorway Pages to Hell.
The Moron Loop-de-Loop sites contains snippets of your site and something that looks like it's a link to your web site but instead it links deeper into itself showing yet another page that is more thematic based on what you clicked. You can click and click and go round and round in this site because the only exits are AdSense exits. This is actually quite ingenious as you get more specific ads related to your area of interest if you keep clicking on more thematic links that seem to narrow your focus of interest but never provide anything interesting, except the ads.
The Loser Landing Strip is an interesting cloaking variation as this supposedly single page web site appears to have an infinite amount of cloaked pages behind it but only Google's IP addresses see that cloaked content, you only seel the silly landing page. No matter what snippet of page content you see in the search engine, no matter what nav links you click on in the web site, it's always that same landing page. All paths lead round and round to the same page so just click the ads already and give them what they want!
Door Way Pages to Hell is an interesting variant as it is part Moron Loop-de-Loop and Loser Landing Strip in that the first site you hit looks like a blog with links to actual web sites but the blog is actually the starting point on a trip to hell. Each link in the blog that says it's taking you to a useful web site actually has a link to one of their other scraped content sites instead, which of course link to yet other scraped content sites. It's a freaking AdSense pyramid scheme disquised like a domain park, it's absolutely frightening that someone would build such a large network just to keep a surfer going in circles until they catch a click.
Definitely a new low in scraping as the original content owner gets no value, not even a link, nothing but being used to get keywords and phrases to divert people to their sites.
Not sure it can get much worse than this but I've been wrong before!
Monday, February 13, 2006
Bullshit Gourmet
Sometimes when the little frozen food meals are on sale at the store I'll snap them up to get the 10 for $20 sale price and have a nice quick microwave lunch every now and then. Well, this weekend the fridge was bare and the usual brands weren't on sale at the market so what-the-hell let's see what these Budget Gourmet's are like since they're on sale.
Today is the moment of truth.
Opened one of these little boxes up and it has all the food, what little there is, on one side and all the sauce on the other.
Wait a fucking minute, half of this itty bitty box is reserved for a thin layer of sauce?
You must be fucking joking.
Completely unsatisfied ripped open yet another box.
Same bullshit, small pile of crap on one side, sauce on the other side.
BULLSHIT!
FUCKING BULLSHIT!
I'M STILL HUNGRY AND I'VE JUST BEEN FUCKED IN THE ASS BY A FUCKING FROZEN FOOD COMPANY AND NOW I'M FUCKING PISSED!
McDonald's anyone?
Sunday, February 12, 2006
Cloaking Scrapers Busted
Yesterday was a sad day for one Russian scraper that just had a large number of websites busted for cloaking in Google and they were just reported to Yahoo today as well.
How they were busted is simple, they scraped my site!
Since my scraper stopper was deployed it's been giving all the scrapers a very unique message which they were happily scraping and including with their additional scraped web content. Wait a few weeks for the search engines to continue to crawl and update and VOILA! this message starts to appear on web sites. Clicking on the website in question and the message didn't appear but clicking on the CACHE copy of the page in Google and there it is, cloaked in all it's glory.
Report these sites and POOF! they are gone.
It's like shooting fish in a barrel and more fun than allowed by law.
Come on you cloaking scrapers, take my pages, I dare you...

